viernes, 4 de noviembre de 2016
miércoles, 13 de julio de 2016
REPLICACIÓN MAESTRO-ESCLAVO
En éste tutorial vamos a realizar una replicación maestro-esclavo de nuestra base de datos.
Vamos a configurar dos maquinas dentro de un mismo segmento de red:
Vamos a realizar un ping para saber
si tenemos red entre el servidor maestro y esclavo para continuar con la
replicación.

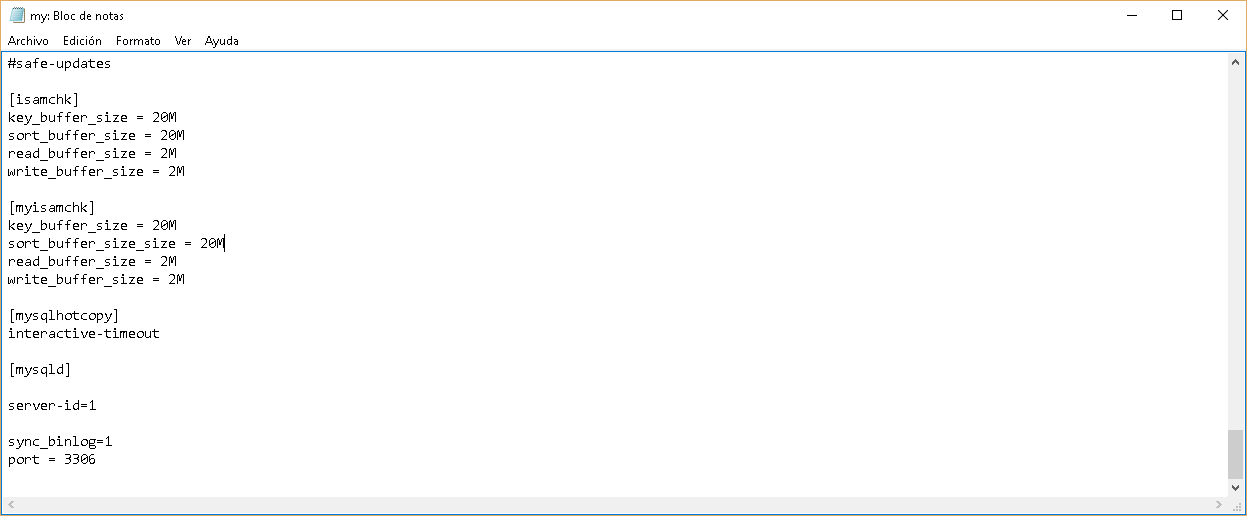
Dentro de wampserver mysql vamos a
configurar el archivo my.ini donde
configuraremos el servidor maestro para que almacene el log binario
(sync_binlog=1) y asignarle un identificador (server-id=1).

Vamos a crear el usuario maestro
para la replicación, que en éste caso será “replica”.

Aquí vamos a dar los permisos de
REPLICATION SLAVE; Tomando en cuenta que el único que podrá tener dichos
permisos es el servidor esclavo con la dirección ip: 192.168.43.86.

Realizamos un SHOW MASTER STATUS
para validar la configuración del servidor.

Ahora vamos a configurar el
servidor esclavo; ejecutamos las siguientes
instrucciones de acuerdo al usuario creado y los valores obtenidos al realizar
el ‘SHOW MASTER STATUS’ en el servidor maestro.

Ahora vamos a realizar un STAR
SLAVE para que inicie la replicación.

CONCLUSIONES
-
Al
momento de crear la replicación nos garantiza tener disponibilidad de
información si llegara a caerse el servidor maestro.
-
Con
la replicación todas las actualizaciones que se realicen en el servidor maestro
se replicarán al servidor esclavo.
RECOMENDACIONES
-
Tener
en cuenta al momento de ingresar las instrucciones al servidor esclavo,
utilizar la ip del servidor maestro y como user al usuario creado de igual
manera en el servidor maestro.
-
Al
momento de asignar los permisos para quien pueda tener la réplica del servidor
maestro, tomar en cuenta la ip únicamente de quien va a tener acceso a la
información.
Lincografía
(s.f.). Obtenido de
http://www.marindelafuente.com.ar/configurando-replicacion-masterslave-en-mysql/
(s.f.). Obtenido de http://www.compilando.es/2011/10/07/configurar-replica-maestro-esclavo-en-mysql-server/
martes, 28 de junio de 2016
Manual Instalación de Slony-I
En el siguiente post voy a realizar un manual con la instalación de SLONY que es un software que nos permite hacer replicaciones maestro/esclavo asíncrono, realizando actualizaciones en cascada.
Slony es un maestro "a varios esclavos" sistema de replicación en cascada de apoyo (por ejemplo - un nodo puede alimentar a otro nodo que se alimenta de otro nodo) y de conmutación por error.
El panorama para el desarrollo de Slony-I es que es un esclavo de replicación del sistema principal que incluye todas las características y las capacidades necesarias para replicar bases de datos de gran tamaño a un número razonablemente limitado de los sistemas esclavos donde se va a realizar la replicación.
Como primer paso tenemos que ejecutar como administrador Application stack Builder.

Seguidamente vamos a elegir elegir a Postgres y el puerto 5432 y siguiente.

Vamos a elegir los bits acorde el sistema operativo. (En mi caso de 64 bits).

Vamos a elegir la carpeta de destino del paquete de descarga de Slony-I.

Clic en siguiente para seguir con la instalación:

Se va a iniciar el gestor de instalación de Slony-I (Setup).

Continuamos con la instalación, en ésta pantalla vamos a verificar que no exista una instalación previa.

Alistamos la instalación, verificamos la carpeta de destino. Por defecto debe instalarse en la carpeta raíz de postgres.

Se finaliza el gestro de instalación de Slony.

Y por último se finaliza el gestor de instalación de Application Stack Builder.

Recomendaciones:
- Verificar que la carpeta de instalación de Slony se encuentre dentro de la carpeta raíz de Postgres.
Espero el manual sea de su ayuda.
Saludos.
lunes, 23 de mayo de 2016
Manual de exportación de Base de datos SAKILA a PostgresSQL
Vamos a realizar un manual con los procedimientos para generar la base de datos SAKILA en PostgresSQL.
 |
Como primer paso debemos realizar la instalación de servidores como WAMPSERVER, XAMPP, MAMP, LAMP, WAMP que sean compatibles con nuestro sistema operativo, en mi caso utilizaré WAMPSERVER que ocupa varios lenguajes de programación como Php, Perl o Phyton, mySQL como servidor web, Apache como servidor web. |
 |
| Ingresamos al lenguaje de programación PHP, (phpMyAdmin), en usuario escribimos root y sin contraseña. |
 |
| Vamos ha realizar la importación de la base de datos SAKILA. Como primer archivo vamos a importar sakila-schema, que viene a ser el DDL. |
 |
| Elegimos sakila-schema para importar. |
 |
| Una vez cargados ambos archivos verificamos que se hayan cargado con éxito los archivos. |
 |
Cuando ya se encuentra cargado la base de datos, vamos a realizar la exportación de la base de datos en fomato mysql para posteriormente ser cargado en PowerDesigner. |
 |
Ingresamos a PowerDesigner en el cuál vamos ha realizar la Ingeniería Reversa de la base de datos (Reverse Engineer) para generar el modelo físico. |
 |
| Vamos a agregar el Driver de ODBC Postgres. |
 |
Elegimos el tipo de origen de datos para que sea aplicado únicamente en nuestro equipo.
|
 | ||||||||||||||||
Seleccionamos el PostgresSQL Unicode.
Recomendación:
- Elegir correctamente la versión del psqlodbc para que no tengan inconvenientes en la conexión del servidor.
Espero sea de ayuda éste pequeño manual.
Saludos.
By Adrian Carrión Alvarez
|




{kind=link}
Suscribirse a:
Comentarios (Atom)